
Giving GPT "Infinite" Knowledge
How to give GPT access to large amounts of data


The never-ending stream of information generated each day makes it impractical to constantly train Large Language Models (LLMs) with new, relevant data. Besides, some data remains private and inaccessible. Depending solely on the LLMs’ training dataset to predict the next set of characters for a specific information retrieval question isn't always going to lead to an accurate response. This is when you might start seeing more hallucinations.
The OpenAI GPT models have their knowledge cut off in September 2021, and Sam Altman recently admitted that GPT-5 isn't their main focus.
This makes sense, given the purpose of LLMs is to understand and interpret language. Once these models achieve a high level of comprehension, training larger models with more data may not offer significant improvements (not to be mistaken with reinforcement learning through human feedback). Instead, providing LLMs with real-time, relevant data for interpretation and understanding can make them more valuable. OpenAI’s code interpreter and plugins are showing how powerful this can be.
So, how can we provide LLMs with loads of data and ask them questions related to it? Let's dive into these core areas at a high level:
Tokens
Embeddings
Vector Storage
Prompting
Tokens
If you are familiar with any of the several LLM models, you know that there are token limitations for the initial prompt (context) and response it generates (or the entire chat if you are using chat completion for GPT). Each model is trained on a number of tokens that sets this initial limitation. This token limit is also the reason you can’t take hundreds of large documents and inject it directly into the prompt for the LLM to then create an inference from. Here are the limits for some of the most popular models today:
GPT-4 - 8,192 tokens (there is a 32k token version that is being released slowly)
GPT-3.5 - 4,096 tokens
Llama - 2,048 tokens
StabilityLM - 4,096 tokens
Using OpenAI's token-to-word estimation, we can assume that 1,000 tokens are 750 words. Even though an 8k token model can accommodate approximately 10 pages of text in the initial prompt with some tokens remaining for the model response, there is still a constraint on the specific data set and the length of the conversation before it loses context. But what if you want to supply the model with thousands of documents to interpret and answer questions about, allowing it the flexibility to "decide" which documents are relevant to the question before responding? Let’s start by exploring how the data needs to be stored.
Embeddings
Embeddings are vector representations of a given string, which simplifies their integration with various machine learning models or algorithms. Here's an example of OpenAI's popular embeddings API (another open source version):
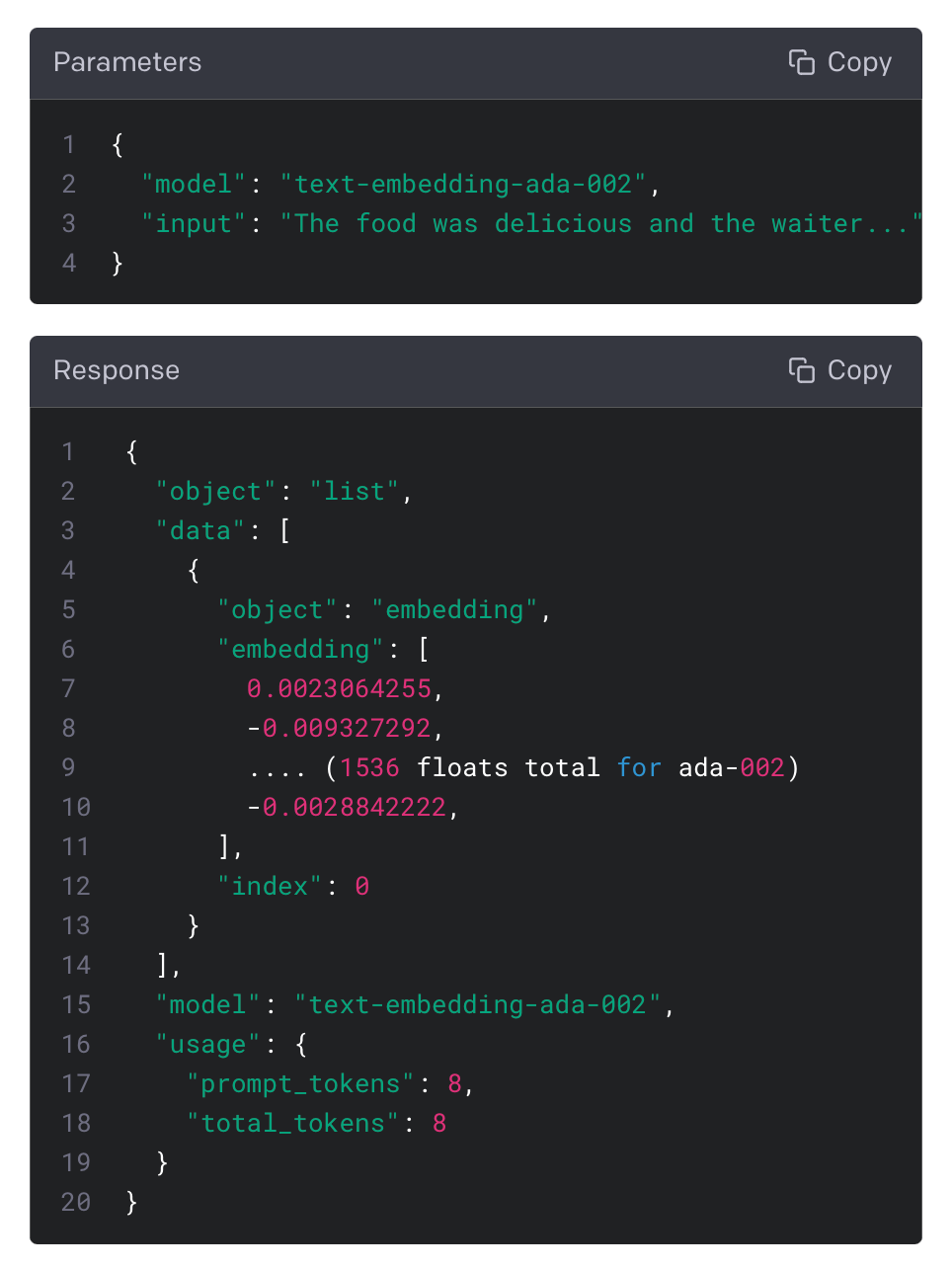
Storing vast amounts of text and data as vectors enables us to extract only the essential pieces related to a specific question before injecting into the LLM prompt. The order of what we are trying to accomplish includes:
Generate embeddings for all your documents and store them in a vector database (we will get into this later)
When a user asks a question, create embeddings for the question and perform a similarity search for relevant information (cosine similarity being a popular method).
We only inject the relevant text, up until the token limit, into the prompt before asking the AI to answer the user’s question.
Embeddings based search isn’t the only solution for this but it is the most widely used right now with LLMs like GPT (lexical-based search and graph-based search being other options). Some services might combine multiple methods.
Vector Storage
There are a number of services that you can use to store vector data. Here are a few:
Regardless of your specific use case, vector storage enables you to reference extensive documents, previous chat conversations, and even code when interacting with the LLM. This provides the capability to create a "memory" or knowledge base for your AI.
Here is a simple example of using Pinecone to store text after generating its embeddings using the OpenAI API:

To search for relevant data related to a given query, we can do the following:
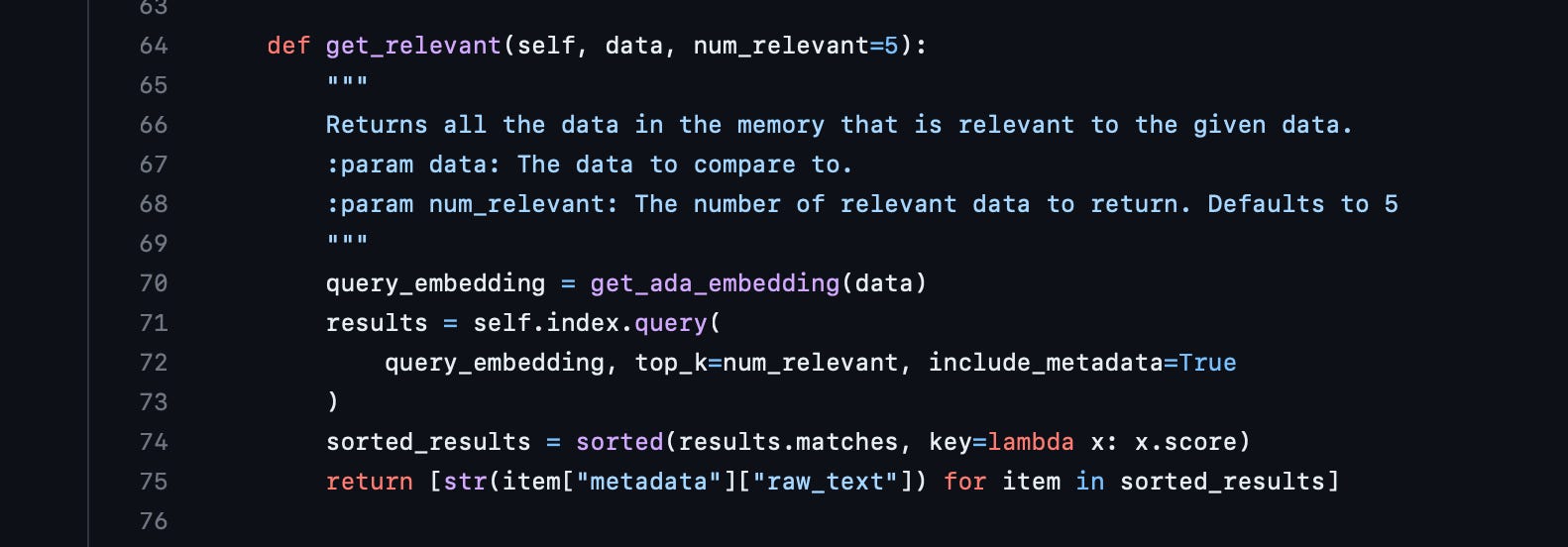
In this example, the developers of AutoGPT retrieve the top 5 most relevant data points from the database. This is where you can be flexible with how much data you pull from storage to add to your prompt while being aware of the token limitations. This makes monitoring token count crucial as you fetch data and construct your prompt. OpenAI has developed a library that enables you to tokenize text and count the number of tokens being used:

num_tokens = len(enc.encode(string))As you are pulling relevant information for a given query, you want to make sure the token count doesn’t exceed the token limit, which includes both the initial prompt and the allocated amount for the LLM response.
There are some interesting techniques that might help accommodate even more data within the token limit. For example, using string compression. However, my own testing of this approach was inconsistent to get back the exact text.
Prompting
Having converted our data into embeddings and stored it in a vector-based database, we are now ready to query it. Constructing the prompt is where you have even more flexibility depending on your specific use case. Here’s a simple example:

Creating this prompt can be as straightforward as providing instructions to utilize the given context (where you inject the relevant text search results) to answer the user's question (where you inject the user's question itself). With GPT’s chat completion API, you can make the direction and context the system prompt and the question a user message.
There is an important part of this prompt that is partially cut off from the image:
“If you don't know the answer, just say that you don't know, don't try to make up an answer”
This statement helps mitigate hallucinations and prevents LLMs from making up answers when the necessary data isn't explicitly provided in the context.
Real Time Data
In the examples mentioned above, we focused on static data that is pre-processed and stored prior to initiating a conversation with the LLM. But what if we want to fetch data in real-time and allow the LLM to reference it for answering questions? This is where we get into the world of autonomous agents and giving LLMs the ability to execute commands like searching the web. For a brief overview on how autonomous agents work you can check out the previous article:
Technical Dive Into AutoGPT

If you haven't heard about the open-source project Auto-GPT, then definitely check it out before continuing. Auto-GPT uses various techniques to make GPT autonomous in completing tasks centered around a specific goal. The project also provides GPT with a list of executable commands that help it make actionable progress towards the overall objective.
Conclusion
By following the steps outlined above, we can collect data, generate embeddings, store them in a vector database, search for n relevant items, and provide our AI with knowledge. However, there will still be use cases where this isn’t enough, and the data that needs to be analyzed exceeds the token limit: such as attempting to inject decades' worth of stock data all at once. As information continuously evolves, we can expect ongoing improvements and creative solutions to be developed.
Looking to interview startups or engineers building with LLMs. Reach out: samir@sudoapps.com.
I tend to think that this is simply a hardware and software architecture and dataset classification problem. As dataset selection methodologies evolve, couldn't a large model simply be utilized and trained simultaneously? If NNs are coarsely modeled after mammalian brains, couldn't they also be adapted to walk and chew gum at the same time?
This is missing something, which is that it can be more feasible to continuously update (train) a smaller model with new data while simultaneously being able to run predictions on it atomically between training micro batches. It is not a pie in the sky to do so. This doesn't make sense to do with GPT but it makes sense with a smaller model. This is the simplest such purely neural approach.