
Technical Dive Into AutoGPT
How do autonomous agents work?


If you haven't heard about the open-source project Auto-GPT, then definitely check it out before continuing. Auto-GPT uses various techniques to make GPT autonomous in completing tasks centered around a specific goal. The project also provides GPT with a list of executable commands that help it make actionable progress towards the overall objective.
There is tremendous potential for where this can go from here. Playing around with Auto-GPT myself has yielded interesting results, but looking at the architecture a bit deeper shows the promising upside given its 101k stars, and counting.

To better understand the concepts of Auto-GPT and how it works, we will dive into the following core areas:
Which models are being used
How does GPT have memory
How to make GPT’s responses more reliable
How to parse GPT’s responses
How to give GPT commands that it can execute
Models
At the time of this writing, Auto-GPT only supports OpenAI's GPT models. If you are not familiar with OpenAI, they have well-documented APIs to interact with all their models. Having tested Auto-GPT with gpt-3.5-turbo and gpt-4, I can say that there is still room for improvement, but performance with gpt-4 is definitely resulting in better outputs than gpt-3.5-turbo. All of this, including token limits, can be configured directly in the .env file. Token limits allow you to control the input (context) and output (response) lengths to manage costs.
I have seen some pull requests for integration with LangChain, which should give Auto-GPT access to additional open-source models if that isn't already on their roadmap. We won't delve much into OpenAI APIs or other open-source models here, but having some background understanding of how large language models (LLMs) in general work will be helpful when discussing the next few topics.
Giving GPT “Memories“
GPT models, by design, don't have an explicit memory. However, Auto-GPT addresses this limitation by using external memory modules. There are a few concepts to understand before we can get into how GPT can have memories:
Embeddings
Vector Storage and Search
OpenAI chat completion API
Embeddings are simply vector representations of text, making it easier to work with various machine learning models or algorithms. Auto-GPT uses OpenAI's embeddings API to create embeddings from the GPT text output.
There are many vector storage services available. The ones being used by Auto-GPT are: local storage, Pinecone (3rd party service), Redis, and Milvus (open source service). Pinecone and Milvus have optimized vector search algorithms to search for text embeddings given some relevant context.
Auto-GPT stores embeddings into one of these vector storage services. It then injects context into GPT by searching for relevant vectors to the current task completion session. Here is an important piece of this code:

OpenAI’s chat completion API has the concept of a “system“ role that is used to give GPT its initial identity, constraints and context. In the above snippet, you can see “relevant_memory“ (in its text representation) being injected into the conversation as a reference to past events for GPT. Auto-GPT is also passing the full chat conversation with their appropriate roles to the chat completion API (up until the token limit).
Prompting For Reliable Responses
At the initial start of the conversation, Auto-GPT uses the "system" role to configure constraints and self-performance evaluation. There is a prompt generator where some of these constraints are hardcoded:

To make GPT more autonomous and self-reliant, I can see how these prompts might help guide it in that direction. There have been a number of examples of improved output from GPT when there is a continuous feedback loop for GPT to self-improve its output. I am not sure if the self-performance evaluation prompts below achieve that same effect, but I can see how this might at least lay the groundwork:

These are additional prompts appended to the same initial role. One to point out, though: "Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps." Since we will look at commands and how GPT will execute each one later, this line is important and makes sense to include to ensure the responses are as efficient as possible, keeping costs minimal by not taking unnecessary steps (using more tokens).
Interpreting The Response
This is likely the most important aspect of the inner workings of Auto-GPT. Without being able to interpret the response efficiently, you can't allow GPT to execute commands (give it access to the outside world). Auto-GPT uses a fairly simple but powerful prompt technique to ensure GPT responds in a fixed JSON format that can then be parsed by code:

In my own testing of prompting with a fixed response format, using gpt-3.5-turbo, has proven to be pretty effective, with some occasional hallucinations (assuming gpt-4 is much more reliable). This is also where we instruct GPT on how to execute commands, which we will examine next. When GPT wants to execute a command, it will include the information within the "command" object.
Interacting With The Real World
Autonomous agents are only useful if they can actually perform work for you and interact with the real world, whether that’s your file system or the internet. Auto-GPT first has to code each command that it wants to give GPT access to execute. In the initial prompt generation, where constraints and self evaluation are provided, the list of executable commands and their parameters are also provided. Here is the class function to add commands to the prompt:

In the base prompt generator there is a pre-defined list of commands (this file seems to have changed recently and might not reflect what is current):
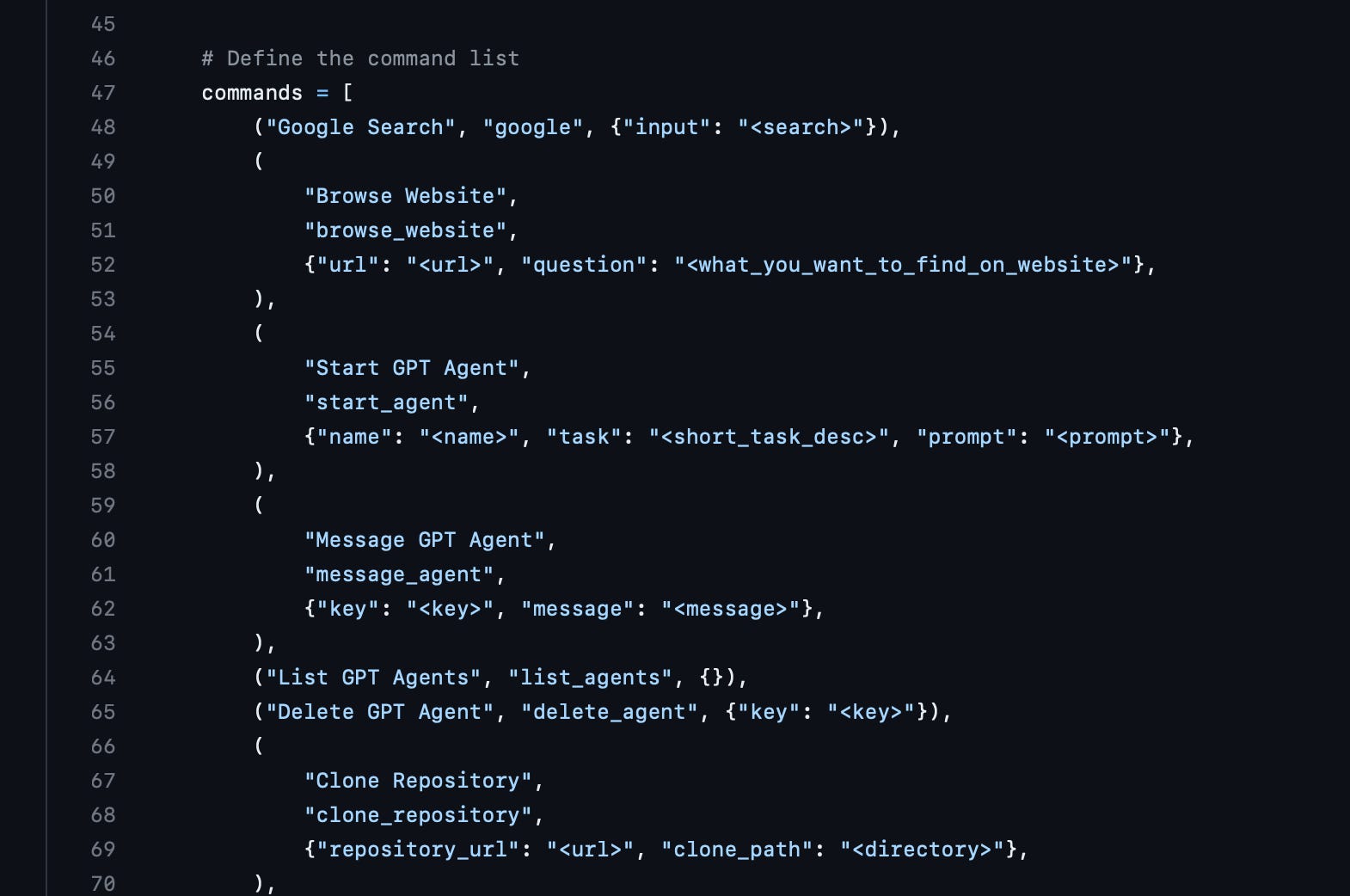
This format is what GPT will reference for commands that it can execute with their parameters. Here is how the final prompt is formatted as a string to GPT:

As you can see, this is where everything comes together. This prompt gives GPT its constraints, self-evaluation direction, resources, commands, and response format. Now, when parsing the response back from GPT, the command that it wants to execute and parameters are clear. The last step is to execute the command (this code has been recently improved, so it may not reflect what is current, but I believe it makes it easier to understand the command execution for the purposes of this post):
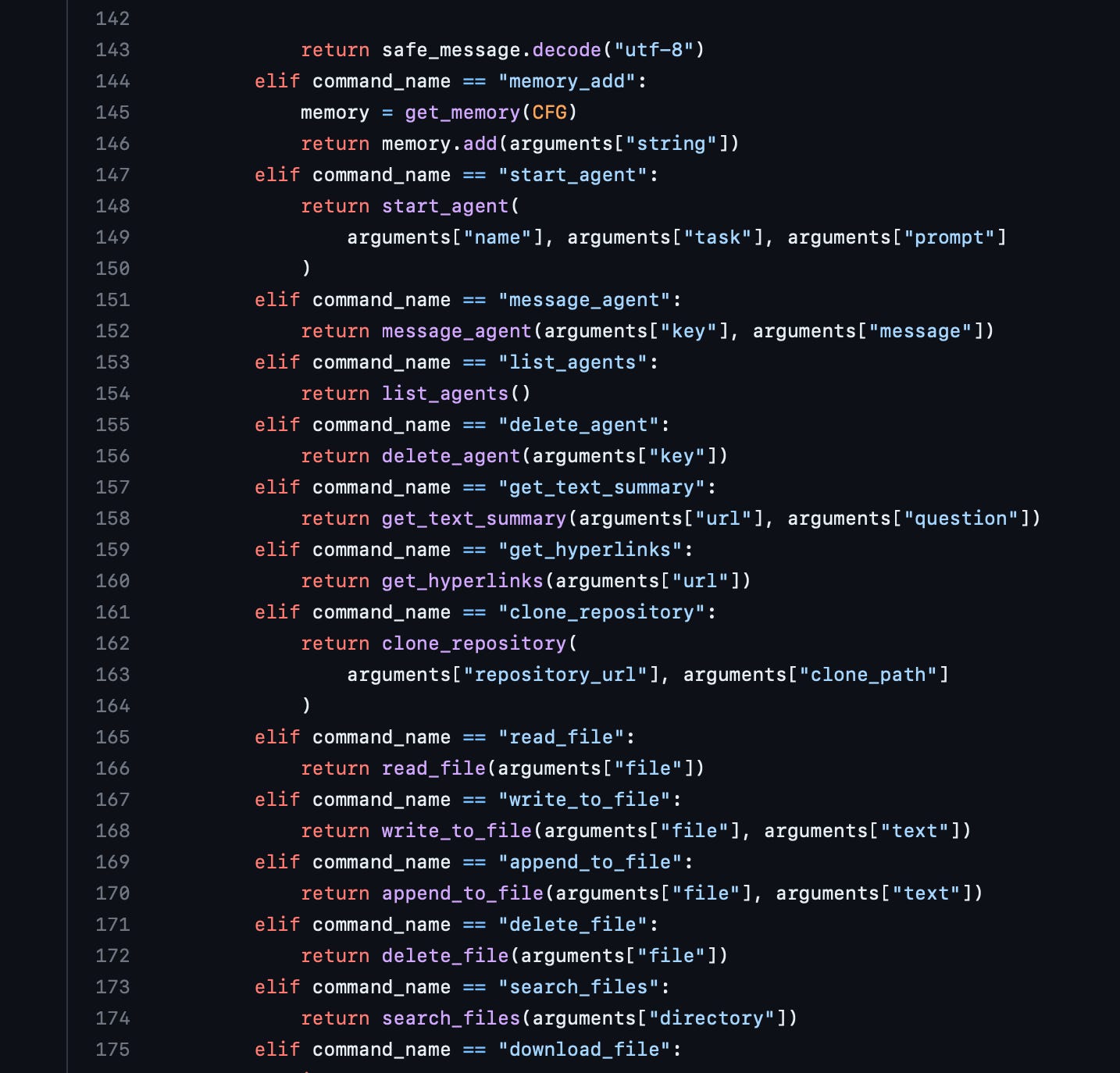
Here, each command is mapped and executed with its arguments after being parsed from the GPT response. One of the commands for GPT is also "task_completed," which, if you are running in continuous mode, will allow the program to shut down or exit when GPT thinks it has achieved its goal:

BabyAGI
Another popular experiment with autonomous agents is BabyAGI. This project uses similar concepts but greatly simplifies the implementation (with fewer overall features). It supports LLaMA and OpenAI as model inputs. After providing the objective and initial task, three agents are created to start executing the objective: a task execution agent, a task creation agent, and a task prioritization agent. Each agent has its own prompt and constraints, including context from each related task execution. This process is done in a continuous loop until there are no tasks remaining and the objective is complete.
Both Auto-GPT and BabyAGI have gained a lot of traction and are continuously being improved.
Conclusion
There is definitely a lot more involved in these projects to make them perform as well as they do. These projects are an exciting step forward in the world of AI, bringing us closer to a future where AI can autonomously complete tasks and assist in various aspects of our lives. This is mean’t to highlight some of the core concepts that can help others understand its inner workings and possibly contribute to this new world of autonomous agents.
Looking to interview startups or engineers building with LLMs. Reach out: samir@sudoapps.com.